
MySQL中(JOIN/ORDER BY)语句的查询过程及优化方法
网站或服务的性能关键点很大程度在于数据库的设计(假设你选择了合适的语言开发框架)以及如何查询数据上。我们知道MySQL的性能优化方法,一般有建立索引、规避复杂联合查询、设置冗余字段、建立中间表、查询缓存等,也知道用EXPLAIN来查看执行计划。
但对MySQL复杂查询语句执行过程和内部机制,MySQL Optimizer本身所做优化以及查询语句调整对性能所产生的影响及其原因知之甚少。
本文试图对其中的一些关键概念如执行过程、索引使用等做比较深入的探讨,知其然,知其所以然,这样可以避免在原本通过MySQL简单优化就能获得很好效果的情况下,盲目跟风转向NoSQL存储或者投入资金升级基础设施。
工欲善其事,必先利其器,这里首先介绍MySQL查询语句性能分析工具。
MySQL的EXPLAIN命令是用来分析查询性能的工具,EXPLAIN的输出每一行对应于查询语句中的一张表的执行计划说明,其输出列含义如下表:
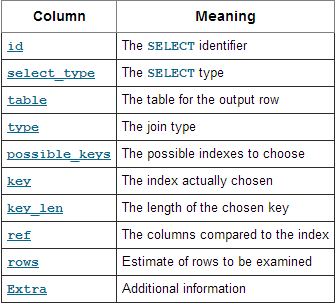
上表中type列是表关联类型,常见的有如下类型(按关联查询效率从高到低排列):
const(常量连接),比如SELECT * FROM user WHERE id=1;
eq_ref(等值引用),比如SELECT * FROM user,card WHERE user.id=card.userid;
ref(引用),用于非唯一索引,比如SELECT * FROM user,card WHERE user.last_name='test';
range(范围),比如SELECT * FROM tbl_name WHERE key_column > 10;
index(索引),根据索引来读取数据,如果索引已包含了查询数据,只需扫描索引树,否则执行全表扫描和All类似;
ALL(所有),全表扫描
key列代表索引(index),rows表示估计会扫描多少行记录,
Extra表示附加信息,常见的有如下几种(也按查询效率从高到低排列):
Using index:表示使用索引,如果同时出现Using where,代表使用索引来查找读取记录,如果没有Using where,表示索引包含查询数据,无需额外的查找;
Using where:表示条件查询,如果type列是ALL或index,而没有出现该信息,则你有可能在执行错误的查询:返回所有数据;
Using filesort:不是“使用文件索引”的含义!filesort是MySQL所实现的一种排序策略,通常在使用到排序语句ORDER BY的时候,会出现该信息;
Using temporary:表示为了得到结果,使用了临时表,这通常是出现在多表联合查询,结果排序的场合;
如果EXPLAIN出现后面两个信息(Using filesort,Using temporary),而rows又比较大,通常意味着你需要调整查询语句,或者需要添加索引,总之需要尽量消除这两个信息。
下面给出EXPLAIN结果实例(从用户档案表中找出昵称和性别,按用户表中的用户关注者数量排序):

可以看到上述的查询需要检查1万多记录,并且使用了临时表和filesort排序,这样的查询在用户数快速增长后将成为噩梦。
在优化这个语句之前,我们先了解下SQL查询的基本执行过程:
1.应用通过MySQL API把查询命令发送给MySQL服务器,然后被解析
2.检查权限、MySQL optimizer进行优化,经过解析和优化后的查询命令被编译为CPU可运行的二进制形式的查询计划(query plan),并可以被缓存
3.如果存在索引,那么先扫描索引,如果数据被索引覆盖,那么不需要额外的查找,如果不是,根据索引查找和读取对应的记录
4.如果有关联查询,查询次序是扫描第一张表找到满足条件的记录,按照第一张表和第二张表的关联键值,扫描第二张表查找满足条件的记录,按此顺序循环
5.输出查询结果,并记录binary logs
显然合适的索引将大大简化和加速查找。再看一下上面那条查询语句,除了条件查询外,还有关联查询以及ORDER BY即排序操作,
那么让我们进一步了解下关联查询(JOIN)和ORDER BY是怎么工作的,MySQL有三种方式来处理关联查询和数据排序:

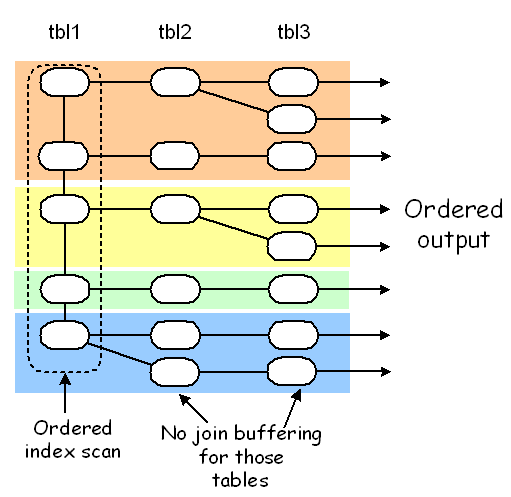
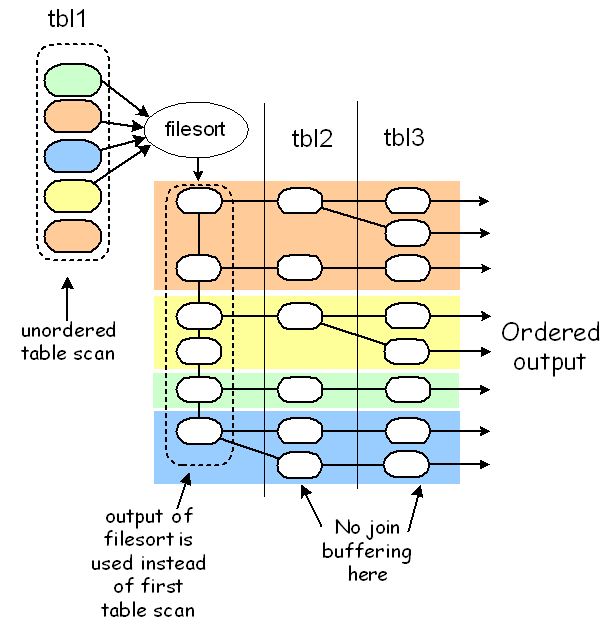
第一种方法是基于索引,第二种是对第一个非常量表进行filesort(quicksort),还有一种是把联合查询的结果放入临时表,然后进行filesort。
注1:关于什么是非常量表,请参考阅读MySQL开发手册:Consts and Constant Tables,
注2:什么是filesort呢,这不是字面意思的文件排序,filesort有两种模式:
1、模式1:排序后的元素涵盖了要输出的数据。排序结果是一串有序序列元素组,不再需要额外的记录读取;
2、模式2:排序结果是<sort_key,row_id>键值对序列,通过这些row_ids再去读取记录(随机读取,效率低下);
注3:关于什么是临时表,请参考阅读MySQL开发手册:How MySQL Uses Internal Temporary Tables
第一种方法用于第一个非常量表中存在ORDER BY所依赖的列的索引,那就可直接使用已经有序的索引来查找关联表的数据,这种方式是性能最优的,因为不需要额外的排序动作:
第二种方式用于ORDER BY所依赖的列全部属于第一张查询表且没有索引,那么我们可以先对第一张表的记录进行filesort(模式可能是模式1也可能是模式2),得到有序行索引,然后再做关联查询,filesort的结果可能是在内存中,也可能在硬盘上,这取决于系统变量sort_buffer_size(一般为2M左右):
第三种方法用于当ORDER BY的元素不属于第一张表时,需要把关联查询的结果放入临时表,最后对临时表进行filesort:
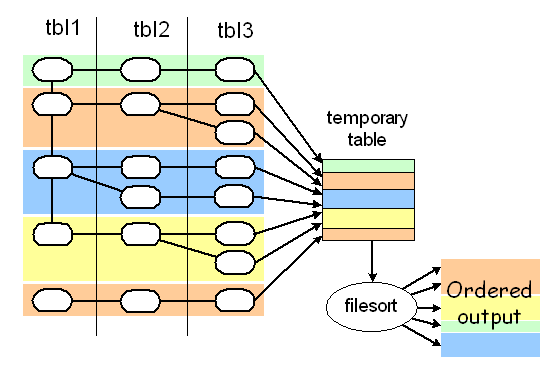
第三种方法中的临时表,可能是在内存中(in-memory table),也可能是在硬盘上,一般是下面两种情况会使用硬盘(on-disk table):
(1)使用了BLOB,TEXT类型的数据
(2)内存表占用超过了系统变量tmp_table_size/max_heap_table_size的限定(一般为16M左右),只能放在硬盘上
从上面的查询执行过程和方式,我们应该可以清楚的知道为什么Using filesort,Using temporary会严重的影响查询性能,因为如果数据类型或者字段设计有问题,
在需要查询的表以及结果中存在大数据的字段,而没有合适的索引可用时,都可能会导致产生大量的IO操作,这就是查询性能缓慢的根源所在。
回到文章开头所举的查询实例,它显然是使用了效率最低的第三种方法,我们需要做和尝试的优化手段有:
1、为users.fl_no添加索引(使得排序字段作为索引),为select(使用覆盖索引)和where(避免全表扫描)所使用的字段建立索引。
2、把users.fl_no转移到或者作为冗余字段添加到表user_profile中。(使得排序字段出现在第一张表中)
3、去除TEXT类型的字段,TEXT可以替换为VARCHAR(65535)或对于中文而言VARCHAR(20000)(使得临时表能在内存中进行)
4、如果实在无法消除Using filesort,那么提高sort_buffer_size,以减少IO操作负担
5、尽量使用第一张表所覆盖的索引进行排序,实在不行,可以把排序逻辑从MySQL中移到PHP/Java程序中执行
实施1、2、3的优化方法后,EXPLAIN结果如下:
